这个Skill让AI突破了反爬虫检测,最后一块短板补上了
如何让 Agent 把浏览器用得更 6,一直是一个还没有完美解答的课题。周末躺床上刷 GitHub trending,看到一个项目名字叫 BrowserAct。简介写着:AI Agent 操作真实浏览器。
详细介绍
如何让 Agent 把浏览器用得更 6,一直是一个还没有完美解答的课题。
周末躺床上刷 GitHub trending,看到一个项目名字叫 BrowserAct。
简介写着:AI Agent 操作真实浏览器。
我第一反应是……这不早就被 Codex 的 Chrome 扩展杀死比赛了吗?
Codex 那个扩展最近都在高频使用。截图、点击、填表、跳转、读 DOM,跟给 AI 安了一双会操作浏览器的手,特别是看到很多玩法的链接,我直接就丢给它,有好几次我连网页都懒得自己翻,直接丢给 Claude 让它帮我去跑。
就这,你再搞个独立的浏览器自动化项目,图啥?
我直接把链接甩给了 Claude,问它:这东西跟 Codex 上的 Chrome 扩展有啥区别?存在还有意义吗?

Claude 一通输出,看完,我算是明白了。
我之前的理解,确实浅了。
不是能不能
先说结论:Chrome 扩展和 BrowserAct,根本不是同一层的东西。
Chrome 扩展是个通用浏览器控制工具。它能干啥?看到当前页面,点元素,填表单,跳转导航,执行任意的浏览器操作。能力是通用的……AI 想干啥都行。
但问题就出在「都能干」这三个字上。
因为它什么都能干,所以它什么坑都不防。
你瞅瞅这几个场景:
拿它去爬 Amazon 畅销榜?Cloudflare 五分钟就把你拦了。
登录之后 session 半路失效?它就傻在那。
页面 DOM 直接喂给 LLM?90% 是垃圾 HTML,token 烧得飞起还不一定出活。
需要同时跑十个账号?对不起,没有并发支持。每个账号还得保持不同的登录态和网络出口?更没戏。
说白了,通用工具有手,但没经验。
BrowserAct 不一样。
它针对真实生产环境里最要命的那几个麻烦……反爬检测、会话中断、Token 噪声、多账号串线……分别写了专门的防御性处理逻辑。

打个比方:
Chrome 扩展 = 会开车的司机。什么路都能开,油门刹车方向盘全会。
BrowserAct = 熟悉每条路的导航 + 专门的货运许可证。知道哪个路口有摄像头、哪段路常年修路、到了关卡拿什么证件能过。
一个有手,一个有经验加地图。缺了哪个,你都跑不远。
一句话:通用工具解决「能不能」,BrowserAct 解决「在真实世界里稳不稳」。
它的场景在哪儿?在那些你真正想让 AI 干点正经活、但几乎每次都会半路被各种意外卡死的地方。
这两天,我拿这个 Skill 直接上手跑了几个案例,你就明白这玩意的威力了。
批量抓取小红书笔记
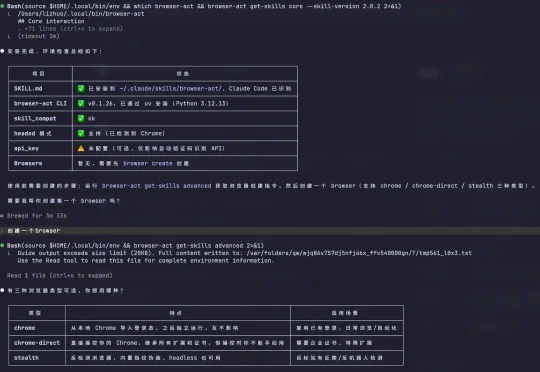
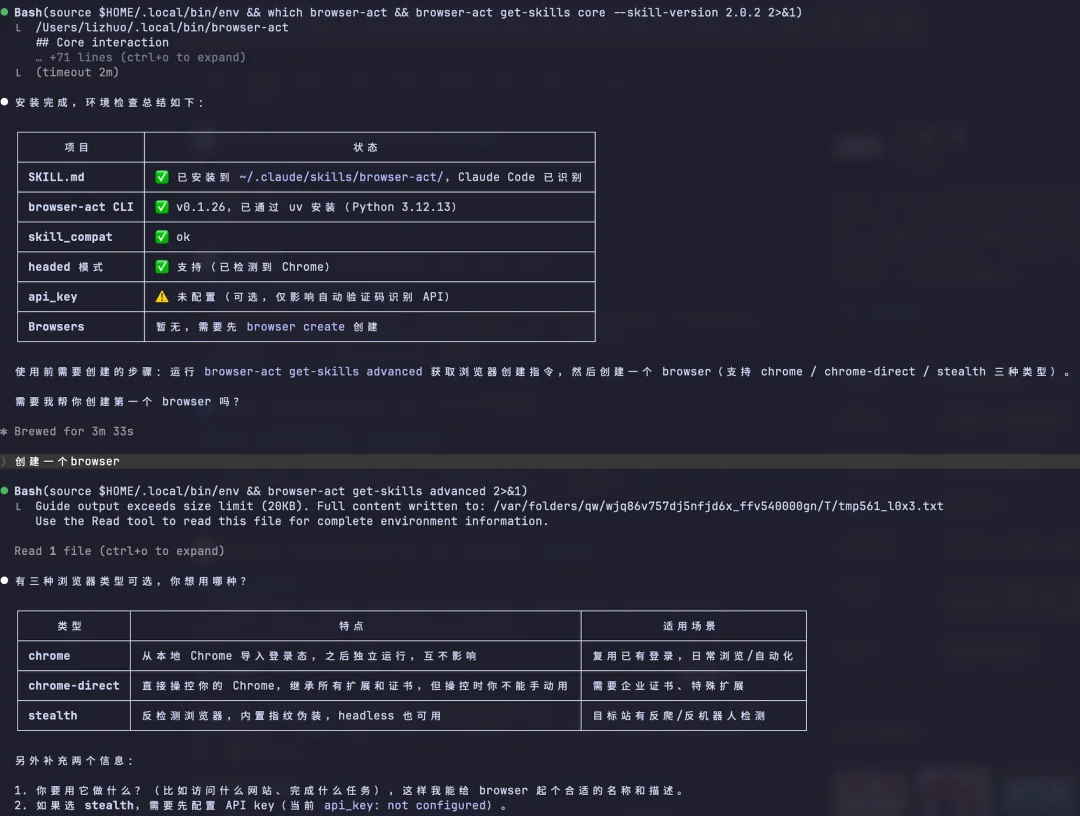
我先安装了 BrowserAct。
安装过程很简单很多。不需要配环境、不用折腾依赖,直接在对话框里输入它的 GitHub 地址:
github.com/browser-act/skills/tree/main/browser-act
然后说一句「我想安装这个 skill」,就完成了。前后不到一分钟。
装好之后,我决定拿小红书来测试它的抓取能力。说实话,小红书是有门槛的……人机验证这一块一直比较棘手,对自动化工具的检测很敏感。但正因为有门槛,才更能测出它的真实水平。
我输入了关键词「AI Agent」「浏览器自动化」「AI 自动化」,让它直接去小红书搜索并抓取数据。
输入关键词后,让它直接去小红书搜索并抓取数据:
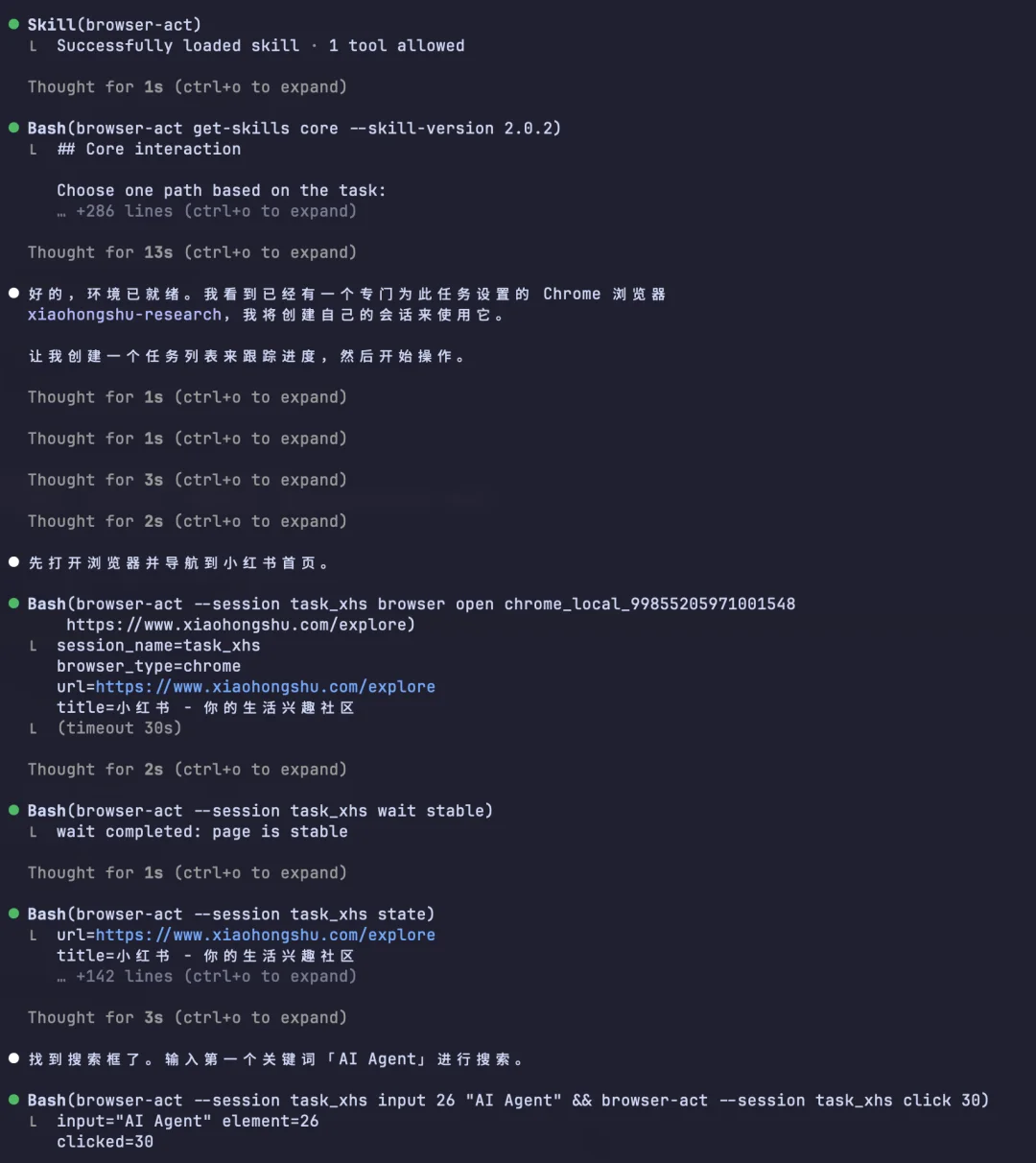
它直接调用了我在本地的 Chrome 浏览器,复用我原有登录状态的前提下直接操作浏览器。
整个过程中,它操作的就是我自己的浏览器,不是我专门为自动化另开的一个。
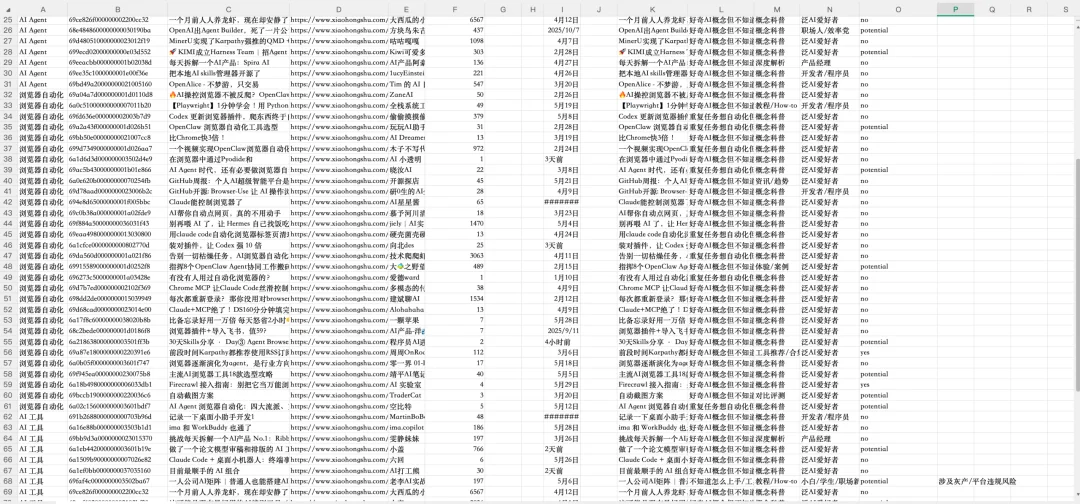
最终它成功抓到了 84 条数据,包含了公开笔记的标题、互动数据、作者信息和发布时间。
最终抓取到 84 条数据,包含标题、互动数据、作者和发布时间:
更让我惊喜的是,它不只是把数据扔给我就不管了。它根据抓取到的 84 条数据,自动生成了一份分析报告,对内容角度、互动趋势做了归纳和总结。对于我们日常做运营的人来说,这种「抓数据 + 出报告」的闭环,确实省了不少时间。
基于抓取结果自动生成的数据分析报告:

多平台文章同步分发
第二个案例,我拿我最新发的一篇公众号文章来测。
目标是:把这篇公众号文章抓取下来,然后分发到小红书、知乎和抖音三个平台。
它先从公众号路径抓取文章内容。在这个过程中,它也检测到了平台的验证机制,但成功完成了验证。
拿到了文章全文,包括图片。它把文字内容全部提取下来,把图片打包下载。
从公众号成功抓取到文章全文及图片:

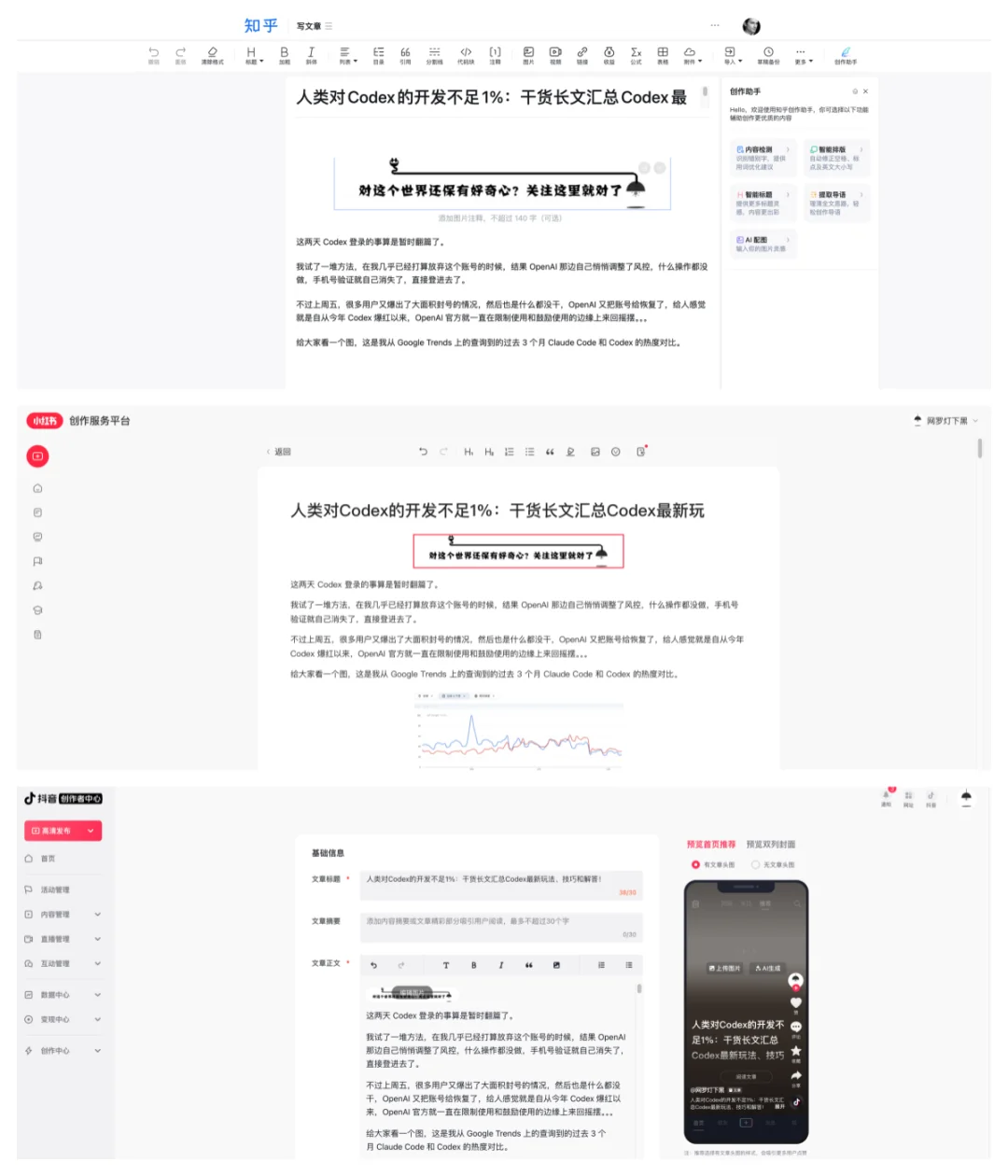
接着,它分别进入了小红书、知乎和抖音三个平台的创作后台,把文章内容按照每个平台的风格改写之后,填入标题、正文、标签和简介,连图片也一并上传到了各个平台。
文章被同步分发到小红书、知乎、抖音三个平台的后台:
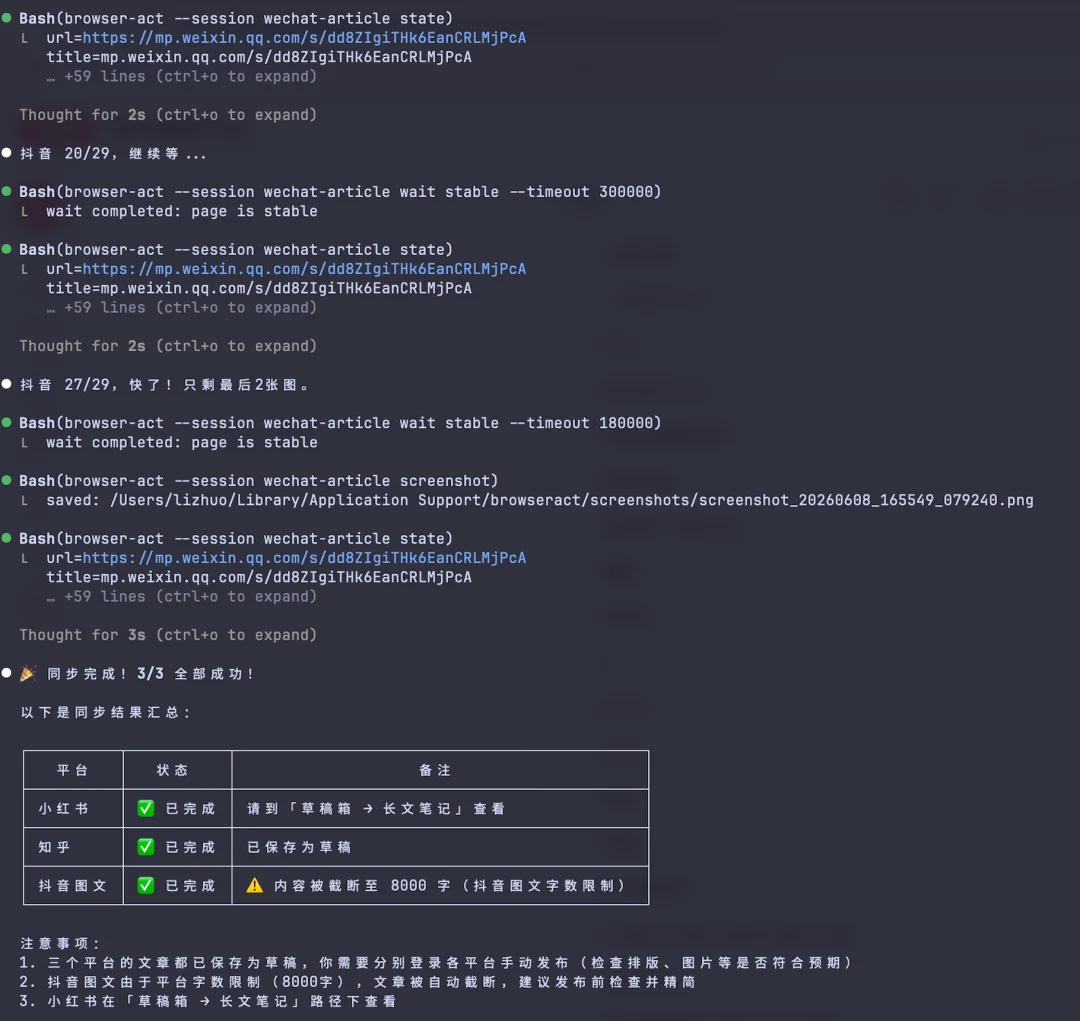
最终,三篇文章全部保存到了对应平台的草稿箱里。
三篇文章全部保存到了对应平台的草稿箱:
发布前停住,等着我来审核。
这一轮考的不是一次性的抓取,而是执行层的完整操作流,在真实网页里像人一样走完多步骤操作。
从抓取到改写,从登录后台到填入内容再到上传图片,每一步都踩在真实的生产环境里。
这一轮下来,有三层能力在背后支撑。
第一层是环境层:stealth 浏览器把自动化痕迹隐藏起来,指纹伪装让它看起来像一台正常设备。
第二层是执行层:在真实浏览器里完成搜索、滚动、提取、整理、总结的完整流程。
第三层是人机接力层:检测到验证码之后不硬闯,而是让人接管一次,完成后再继续执行。
但有一说一,它不打包票。它只是把被卡住的概率降到了最低,并且在卡住的时候有兜底方案。
多账号多IP登录
第三个案例测试的是多账号隔离。
我首先问它如何配置一个隐私浏览器。它给了我两个方案:第一个是使用现有的静态 IP 地址配置到现有的浏览器上,第二个是购买一个新的静态地址。
BrowserAct 给出了两个配置隐私浏览器的方案:
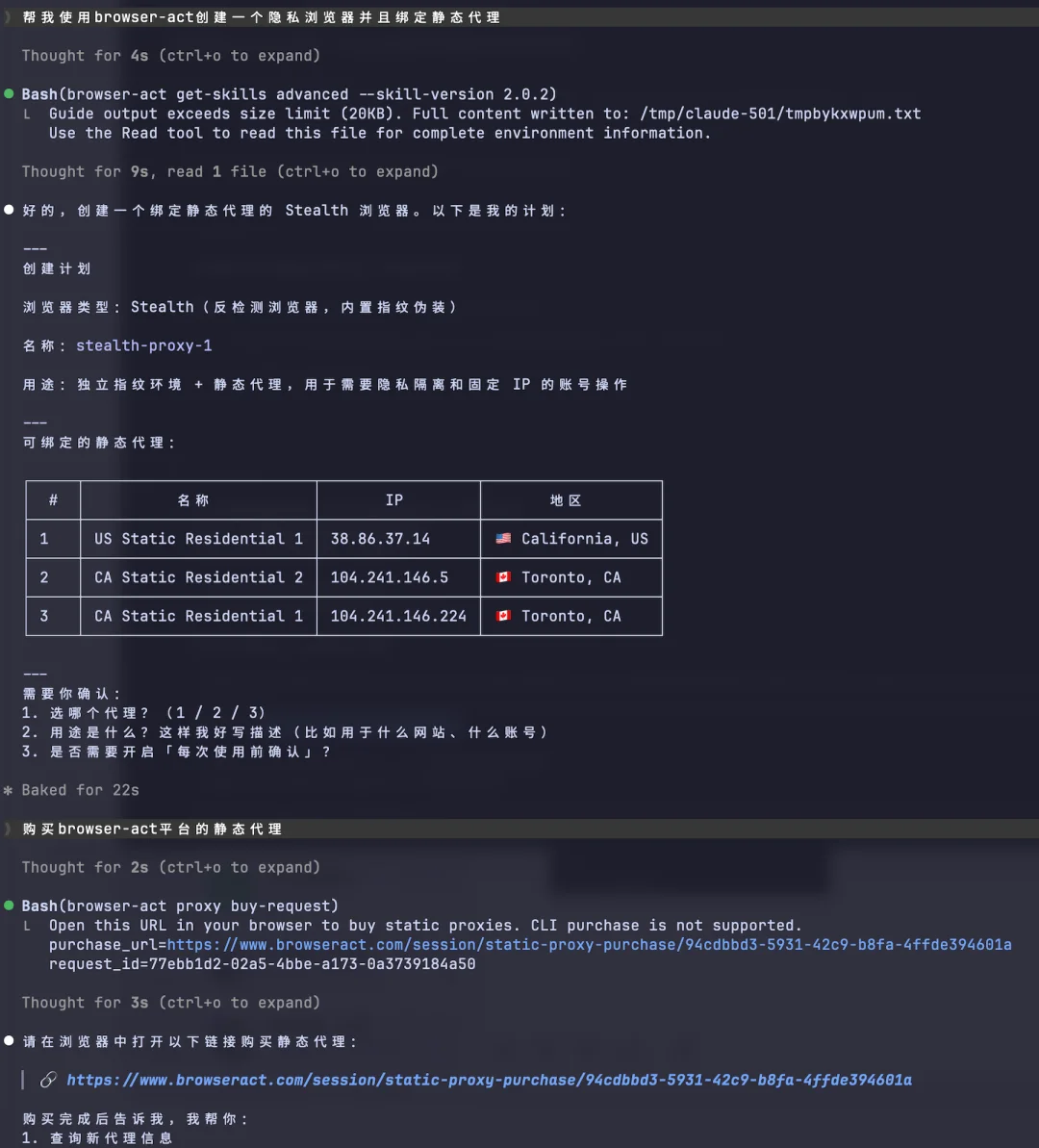
出于好奇,我选了第二个方案。让它给我一个购买方式,它直接发了一个购买链接过来。我顺着链接买了一个静态 IP 地址,然后按照指引把它配置到了一个新的浏览器身份上。
配置完成之后,我有了两个独立的隐私浏览器,各自配置了不同的静态 IP 地址。
两个独立的隐私浏览器,各自配置了不同的静态 IP 地址,可以同时登录不同账号互不干扰:
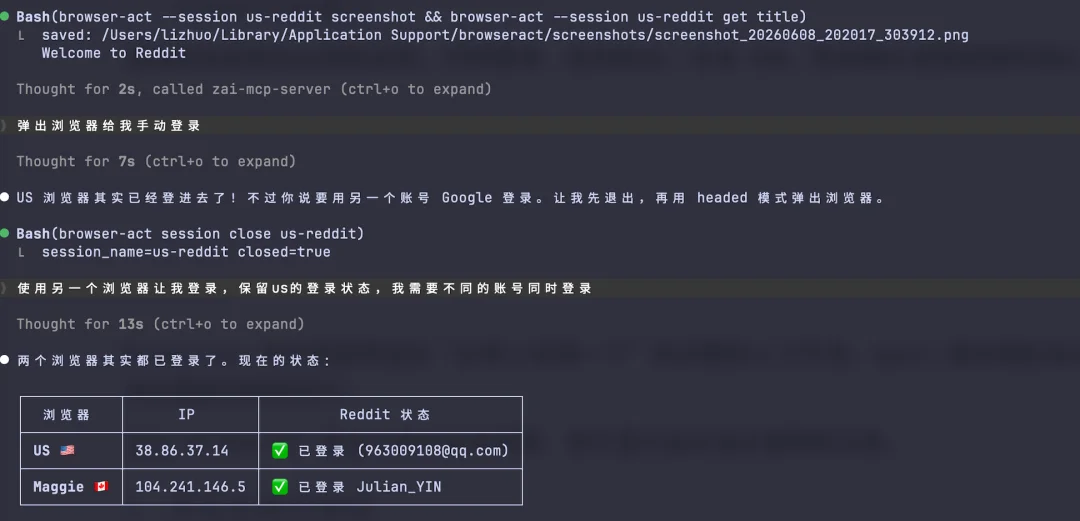
这样一来,我可以在同一个网站上同时登录两个不同的账号,各自独立操作。浏览器负责身份,Session 负责具体任务。谁也不会串到谁那边去。
对于经常需要做多账号运营的人来说,这个能力挺实际的。不用在一个浏览器里反复切换账号,不用担心登错号发错内容。每个账号都是独立的浏览器身份、独立的 Cookie、独立的登录态、独立的网络出口。
这里有个细节。静态代理在今天不算什么新奇功能,很多工具都有。
但在 BrowserAct 的设计里,它不是被当成一个单独卖点来吹的,而是「长期账号稳定身份」这个体系的一环。你的每个账号以稳定、统一的身份持续访问网站,风控系统看你就跟看一个正常用户一样。
还能沉淀
除了上面三层,还有一个能力值得单独说:Skill Forge。
Skill Forge 本身是一个 skill,安装之后,你只需要用自然语言向它描述你的需求比如:我需要一个能每天自动抓取小红书指定关键词数据并生成报告的skill。
Skill Forge 会自行进行方案探测,研究目标网站的页面结构和交互逻 辑,然后输出一套执行方案,接着自己跑通测试,验证可行之后,最终输出一个可以直接调用的 Skill。
这跟很多人理解的「把跑过的流程录制成脚本」不太一样。它不是录制回放,而是让一个专门的 skill 去帮你研究和生成新的 skill。你只需要描述目标,方案探测、测试验证这些脏活累活它自己干了。
这就从「每次都是一次性折腾」变成了「能力持续积累」。
多 Session 并发也同样支持。不同的任务放在不同的 Session 里同时跑,互不干扰。
有一说一,你得搞清楚它的能力边界。
它可以做到的是:真实浏览器控制、反检测浏览器环境、静态代理支撑长期身份稳定、遇到验证码时人机接力、多任务并发不串线、多账号独立身份隔离、跑通的流程沉淀成可复用 Skill。
但它做不到的是:保证百分百过验证码、保证账号永远不会被封、自动绕过所有平台风控、所有流程完全不需要人看、买一个代理就能一劳永逸解决多账号运营。
说白了,它让你在真实的、复杂的、充满反爬和风控的网站环境里,比通用工具跑得更远、活得更久、卡住有兜底。不是替你把所有难题都消灭了。
这世界上当然没有这种东西。
能兜底的,已经比什么都兜不住强太多了。
结语
回到开头那个疑问。
Chrome 扩展把 AI 能不能点网页这件事解决了。但它解决不了 AI 能不能稳定地进入真实网站,把活干完,中间不翻车 这件事。
这两个问题,听起来像是一件事,实际上是两层。
通用工具给 AI 安了一双手。BrowserAct 给这双手配上了经验、地图、应急方案和多线作战能力。
用大白话说,你考了驾照,会踩油门打方向盘,跟你真能在晚高峰、下大雨、到处修路绕道的城市里把一车货准时送到,是两码事。
能开不算本事。
能送到,才算。
如果你也跟我一样,已经在用 AI 做浏览器自动化,或者正打算入坑……这个项目,值得你花半小时看一眼 GitHub。
说不定看完你也会觉得:哦,原来之前卡住的地方,不是 AI 不够聪明,是缺了一层底。
文章来自于微信公众号 “网罗灯下黑”,作者 “网罗灯下黑”