
我做了个测试 Claude API 中转站的 Skill,测完发现水太深了
根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。
详细介绍
昨天一个朋友给我起了个称号,叫「Claude 科学家」。
这个称号的获得,说出来 nm 一把辛酸泪。我的 Claude 官方订阅已经被封了四个原价的 Max 账号,最近又新买了一台 Mac mini,刚用几天又被秒封。
封号封到我怀疑人生。
但问题是,Claude 确实没法替代。你只要深度用过一段时间,就会发现它在文字质量、上下文理解、尤其是一篇长文章的逻辑处理上,远超其他模型。这种差别,真不是玄学。
所以就陷入了一个困境: 我必须用 Claude,但我已经彻底用不了 Claude。
怎么办?只能去找中转站。
中转站我用了两个月。过程中发现一件事:这东西完全是黑盒。你根本不知道接入的模型,背后到底是哪个。然后,我就被当狗骗了。

市面上有一些推荐中转站的网站,倍率标注得清清楚楚。低的 0.3 倍,高的 1.8 倍、2.0 倍,看上去很透明。但你根本看不懂这倍率到底代表什么。
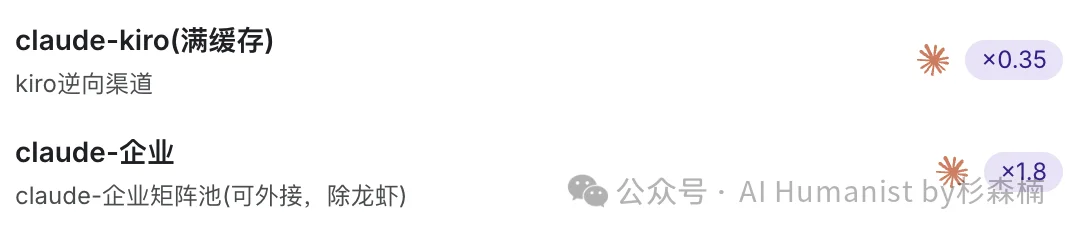
根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。
我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。
我日常完成一件文书类型工作,走完一套工作流,用 0.3 倍率的平台,大概要花 5 毛钱,但是走 2.0 倍率的平台,一次就要花 15 到 30 块钱。而 2.0 倍率的 Claude API,一般意义上,大家会有个共识,那就是正经的 Claude Max 号池接出来的 API。
但用了一段时间之后,我发现了一件很微妙的事。有时候觉得挺聪明的,有时候又觉得不太行,心里始终没底。这种飘忽不定的体验,让我越来越想知道一件事:这玩意儿背后到底是哪个模型?
花了这么多钱,按理说心里应该踏实了。但偏偏相反,我反而更虚了。因为效果完全不确定,有时候感觉还行,有时候明显不对劲。
有种,你都不知道自己是不是交了智商税的错觉。
这就很让人难受了。你说它假吧,有时候确实挺聪明;你说它真吧,关键时刻掉链子。这种反复横跳的体验,比直接用个明知是假的模型更折磨人。
因为你没有办法做一个确定的判断。
所以我决定自己动手,把这事搞清楚。从今年 1 月开始,我花了几个月时间,研究怎么系统地验证一个 API 背后模型的能力,将所有流程封装成了一个 Skill。
开源链接如下:https://github.com/cylqwe7855-alt/llm-api-benchmark-skill
安装命令如下:npx github:cylqwe7855-alt/llm-api-benchmark-skill
先说结论:信中转站,你真的还不如路边拜个野佛。
你怎么知道中转站的 Claude 是真是假?
这个时候,很多人包括我自己都在想一个问题:中转站的模型,到底是不是正经的 Claude?
你心里不踏实,就会想找办法验证。目前市面和各种社区里的方法,基本就这几种。
第一种:直接问。
你上去就问 API:「你是不是 Claude?」
说实话,通过 API 接口写一个完整的系统提示词,这种方式根本识别不出来。太好造假了。背后给你接一个 DeepSeek,改个名字说自己是 Claude Opus 4.8,API 验证层面一点办法都没有。
第二种:稀奇古怪的提示词工程。

用各种稀奇古怪的提示词去套模型,看输出质量,或者看某些奇奇怪怪的输出结果,比如下面这个:
这种方法在 2024 年可能还行,但都两年过去了,中转站连这套都不需要做多复杂的系统提示词就能应对,基本已经彻底失效。这种方法属于是中转站看了都要笑的程度。
第三种:在线检测网站。
有些网站号称能检测 API 中转站是否掺水。我试过,发现整个检测流程在 15 秒以内就跑完了。

这从原理上就不可能。
正常答一道题,模型本身就要花几秒。更重要的是,中转站的 token 输出速度和 API 路径的稳定性本来就有问题。接入量一大,延迟和截断都是家常便饭。15 秒能测什么?测一道题的格式对不对还行,测模型的知识正确率和综合能力,天方夜谭。
那到底怎么办?
我的思路:不测真假,测差距
从今年 1 月开始,我就在研究怎么验证一个模型的能力。
最开始想到的当然是 Benchmark。但调研了一圈发现,这个问题的答案比我想的复杂得多。
一方面,Claude 官方晒出来的那些分数,背后用的数据集确实是内部私有的。比如 Claude Sonnet 4.6 的 System Card 里明确提到,他们测 Terminal-Bench 2.0 时用的是 Terminus-2 harness,思考模式关闭,资源分配做了特殊处理。SWE-bench Multimodal 干脆直接说用了「internal implementation」,分数不跟公开榜单可比。 你拿到手的只是一个最终数字,题库本身根本不公开。
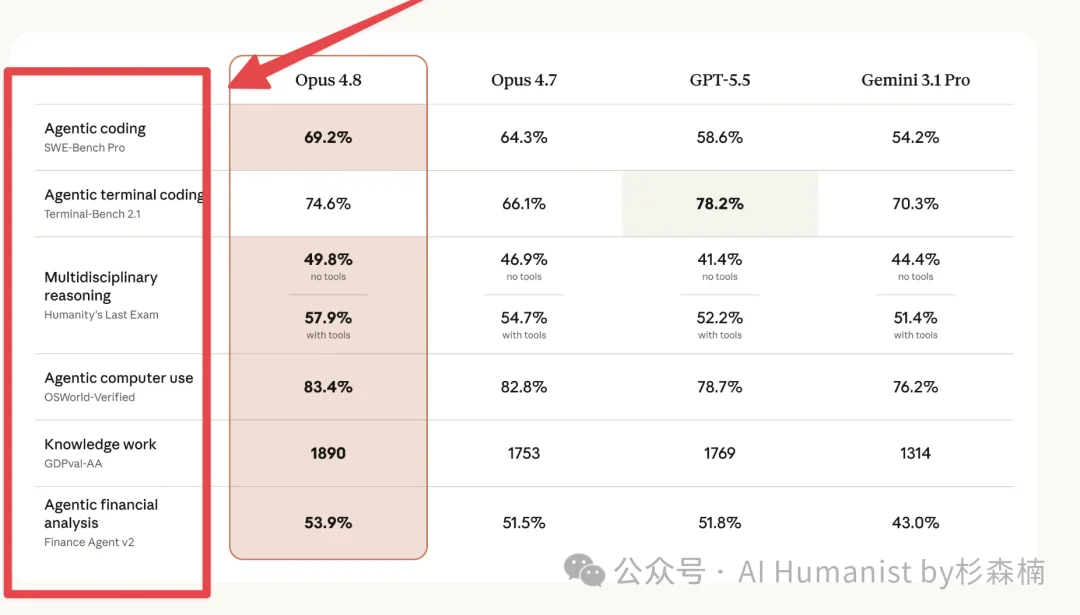
另一方面,大量公开 Benchmark 其实一直都存在。像 SWE-bench Verified、GAOKAO-Bench、C-Eval、GSM8K、MMLU 等等,这些数据集都是开源的,题库稳定,任何人都能测。CAICT 2024 年的一份报告里统计过,当前主流评测数据集中,开源的大概占 69%,闭源只占 31%。
所以问题是:怎么用好这些现成的公开数据集来验证中转站?
调研到这里,我换了个思路。
不一定非要用最新的 Benchmark 啊!既然这么难到手。
这里有一个我夜深人静思考时突然想明白的、反直觉的点:每次 Claude 或者 OpenAI 推出新模型,前半个月到一个月,这个模型本身就是降智的。但无论怎么降智,它肯定还是比很多国产模型强。所以大家的默认认知是:新模型发布之后,默认它已经比上一代强很多,旧 Benchmark 根本没有测试的必要了。
这个认知是大错特错的。
新模型确实比旧模型强,但强归强,旧题库它未必能全做对。而且 Benchmark 的数据集本身是公开的、相对稳定的,用它来做对比验证,反而是最靠谱的方式。
所以我的思路变成了:不追求给出「yes or no」的答案,而是找一个参照物做对比。
找一个基础模型,用同一套题库测出分数,再测你的 API 分数,两个分数一对比,就知道这个 API 到底是掺了水、还是真货。
Skill 是怎么做出来的?
于是,说干就干,我做了一个完整的验证中转站 API 知识能力的 Skill,并做出了一套打分机制。
具体来说,我找 GitHub 上 10 个高 Star 数的项目,每个项目里都有对应的 Benchmark 数据集和验证脚本。

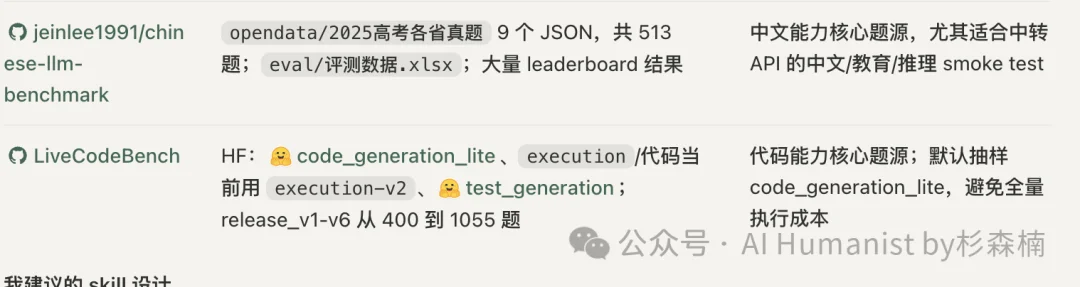
这些数据集来源非常多样,有中文高考题、推理题、数学题、语言题、编程题,覆盖面挺广。
Skill 的设计逻辑是这样的:
第一步,做 API 兼容性。可以接 OpenAI 接口,也可以接 Anthropic 接口。
第二步,从这 10 个项目里构建一个完整的 manifest,等于把数据集统一整合起来。
第三步,按顺序用这些题去请求目标 API。每答完一题就写入 JSONL 文件。
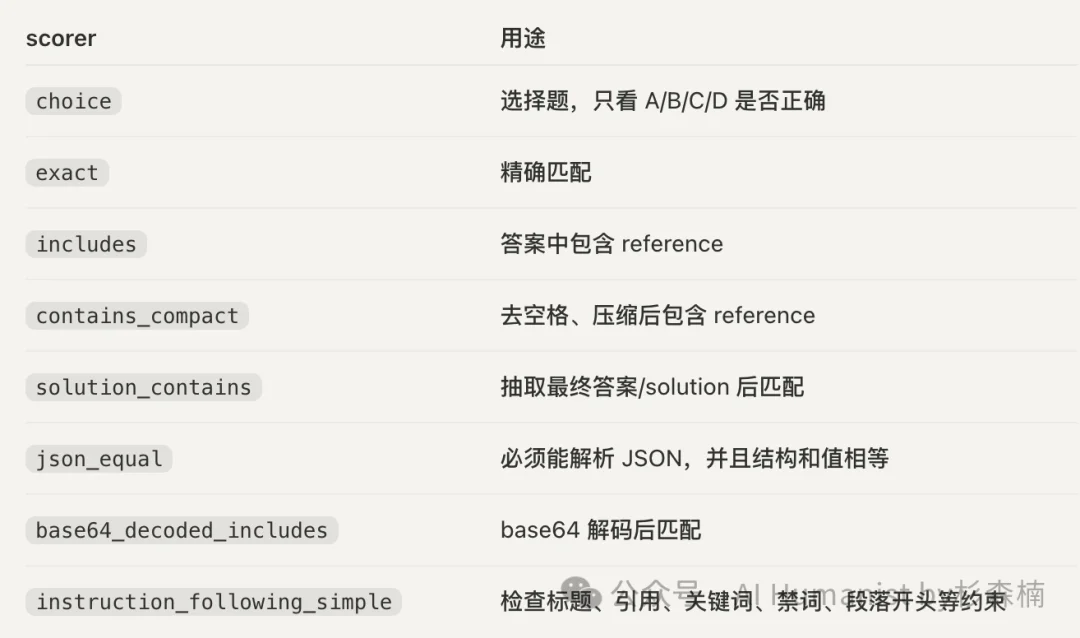
第四步,用打分器判分。有些项目自带打分器,直接用;有些需要自己写。
第五步,所有题跑完之后,把结果聚合成一个加权 MCS 分数。
在实际使用中,我发现中转站 API 非常不稳定,经常会出现截断。这个 Skill 设计了一个关键能力:用 Claude Code 或 Codex 跑的时候,AI 本身会接入能力,当 API 答题被截断时,可以让 AI 帮忙重新做一遍这道题。这样最终评分不会因为格式问题出现大面积零分。
做完之后,这个 Skill 共有 726 道题,从 10 个项目里挑出来的精华部分。每个题目都有一个索引。

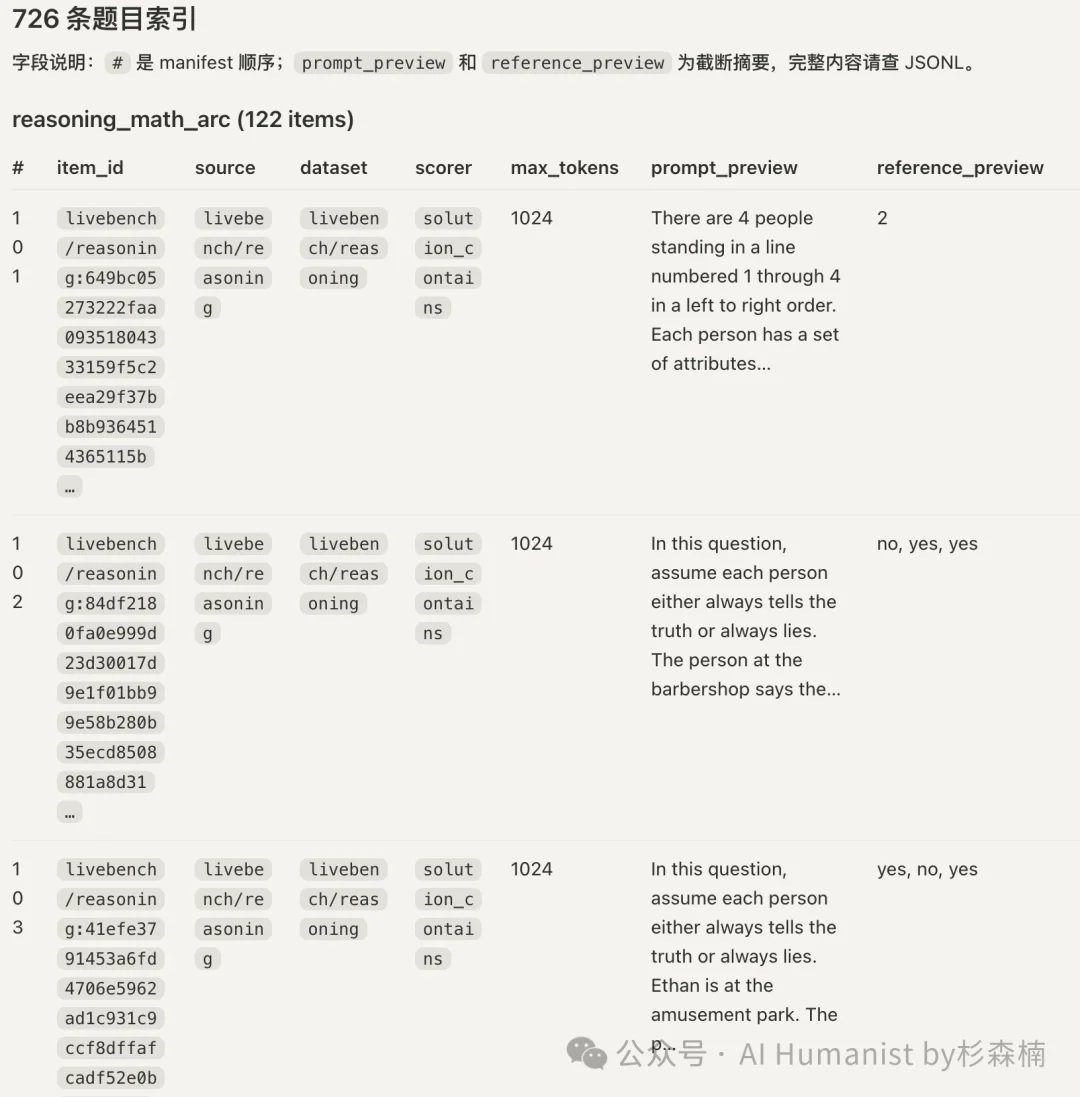
每题会得到一个 item_score,通常是 0 或 1,少数 instruction-following 题目可以是 0.5。
MCS 计算方式是这样的:
MCS = 各能力维度分数 × 权重后的加权平均
测完数据,结果让我心态崩了
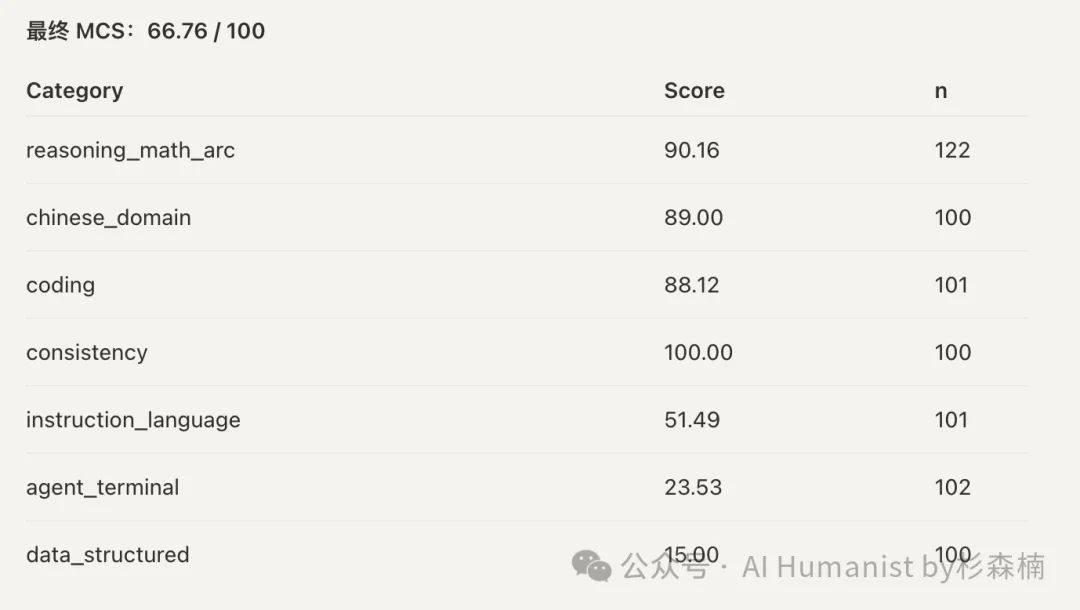
先说基准模型。DeepSeek V4 Pro 这个模型本身效果不错,大家关注度也高。而且 DeepSeek 官方 API 比较稳定,用起来放心。
最终得分:66.76 分,满分 100。在推理、数学、中文、编程几个维度上表现都还行。
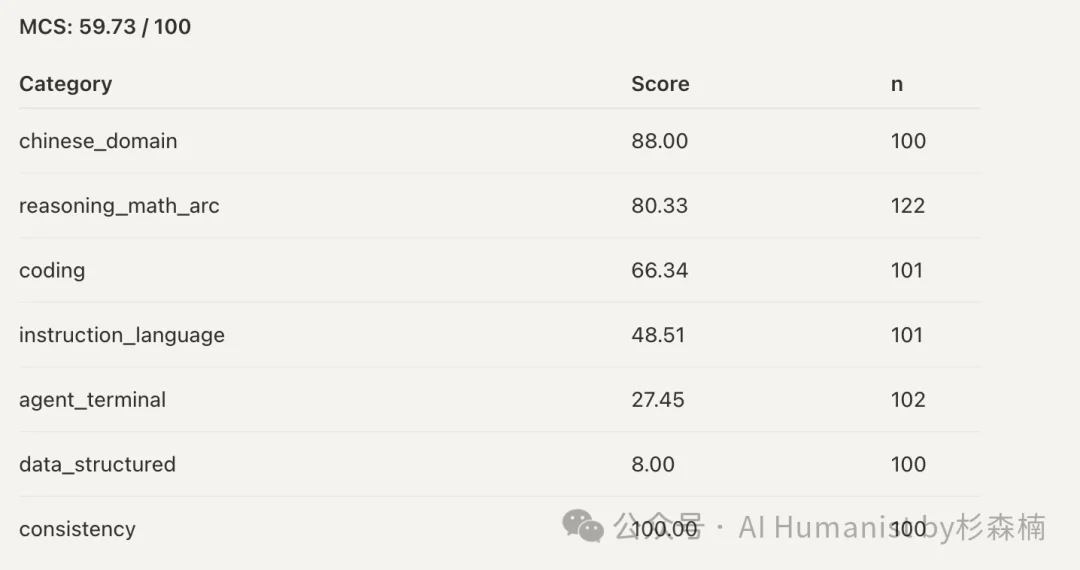
然后就是重头戏了。我一直用的那几家平台,Claude Opus 4.8 的 API。这几家平台是某检测中转站的网站里推荐的,我用了挺长时间,用的时候心里一直犯嘀咕。有时候感觉挺聪明,有时候又觉得不太行。
跑完整个题库之后,心态直接崩了。
您猜猜花了这么多钱买的模型,最后得分多少?
59.73 分。
不如 DeepSeek V4 Pro(当然这里不是在说 DeepSeek V4 Pro 的模型不行)
这家平台在一些结构性数据题目上可能确实不太占优势,但 DeepSeek V4 Pro 同样不占优势。去掉 Data Structure 这一项,它的数学推理、Coding 能力,得分也都低得离谱。
到这一步我人已经麻了。光是一次日常行政任务润色,一次就要花近 30 块钱,结果买了个这。
我不死心,又测了另一家。
这家倍率是 2.0 倍率。在懂行的人眼里,2.0 倍率算是正经 Claude 的基准线。低于 1.5 倍率大家会觉得太便宜不像真的,2.0 倍率大家普遍觉得应该是真货。
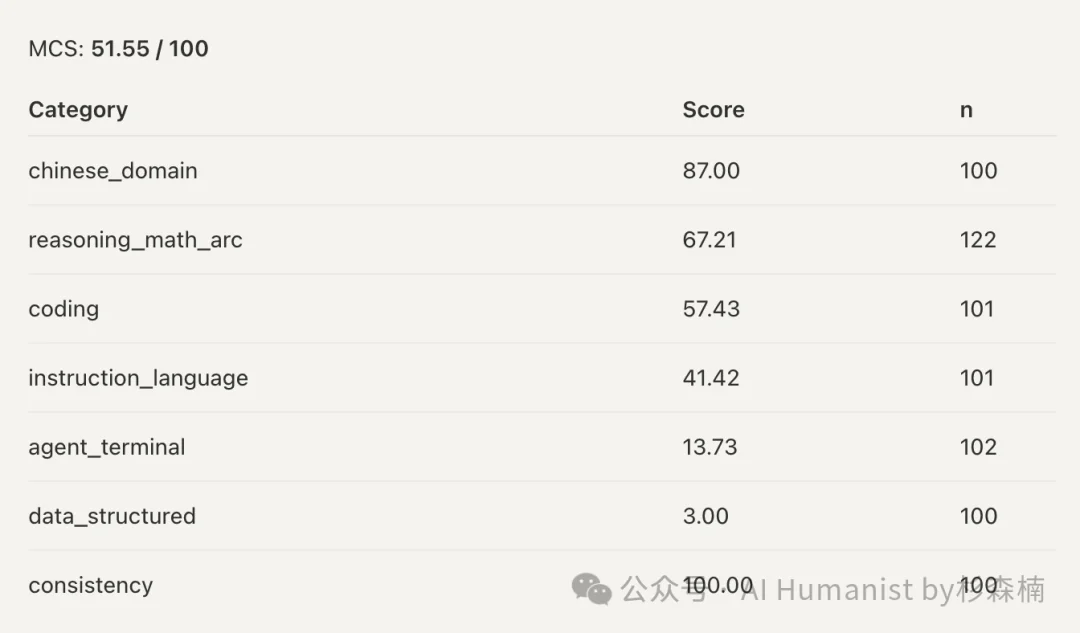
我再跑了一遍。
51.55 分。
推理、数学、编程分数跌得更惨。
到这里,我人整个已经麻了,麻的透透的。
最离谱的是成本。DeepSeek V4 Pro 跑完整套题,用了不到 100 万 token,**花了 9 块 9 毛 7。
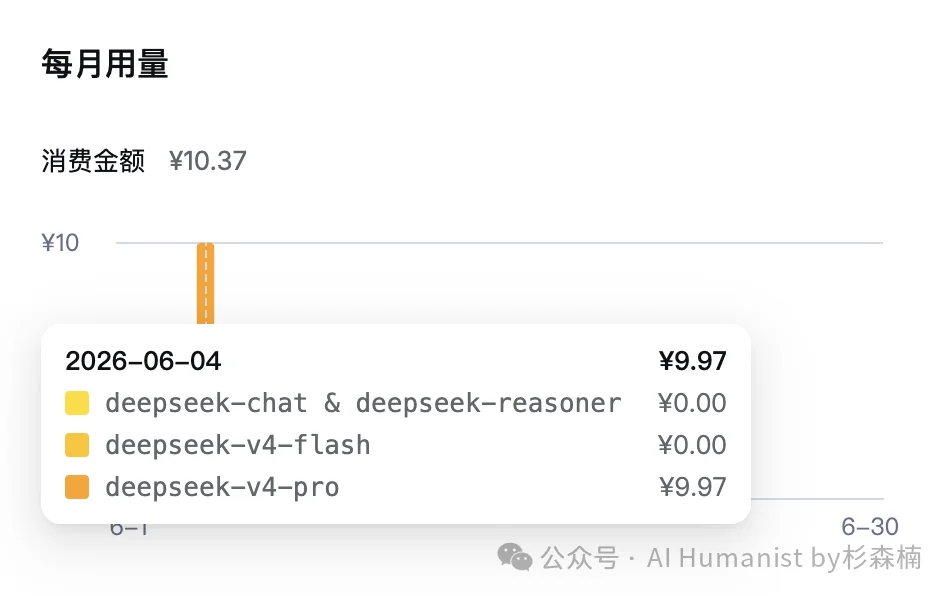
两家自称正经 Claude Opus 4.8 的中转站,一个花了 35 块以上,一个花了近 20 块。
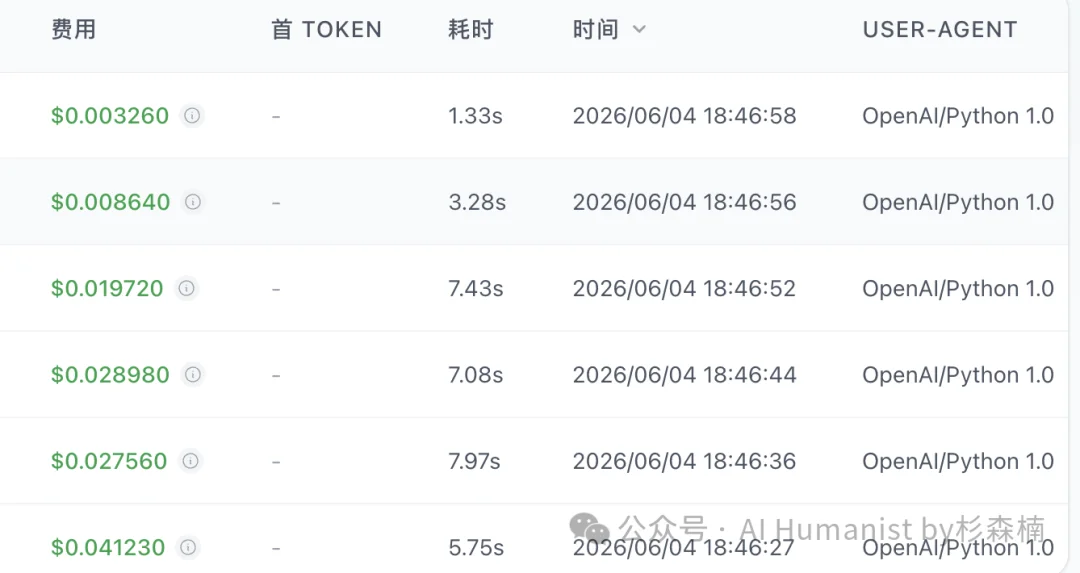
这还是 726 道旧题,跑起来 DeepSeek V4 Pro 大概不到一小时就跑完了,但中转站 API 不稳定,跑了将近两小时。
你就知道那些号称十几秒就能测出模型知识能力的在线检测,有多不靠谱了。
再简单说下,如何跑这个 Skill,我们需要用 Codex 或者 Claude Code,因为它本身依赖 AI 能力来处理截断和异常。如果 50 道题全是零分,问题大概率不在 API,而是打分器或格式出了固定 bug,需要人工介入修复。
叠甲时间
这个 Skill 还是非常初级的版本,用的数据集也比较旧。它只能作为一个小参考,不能拿来判定某个 API 到底是不是正经 Claude。因为官方 Benchmark 你基本拿不到,所以也没办法给出更精准的答案。
当然了,如果有人能非常便捷地测出一个 API 是不是正经 Claude,那中转站这个生意就没法做了,对吧?
但问题是,这个行业连”初级”的验证标准都没有。消费者花着真金白银,连自己买的到底是不是 Claude 都不知道。
这事儿本身就不对。这事儿本身就不对。这事儿本身就不对。(重要事情说三遍)
如果只靠这个 Skill,你依然需要花费 1h 以上的时间去验证,甚至要花 30-50 块钱,这个门槛对验证中转站 API 来说依旧不现实。
如果大家还有什么其他好的验证中转站 API 的想法,欢迎在评论区留言!
最后希望大家玩得开心。
看到这里,辛苦啦。
感谢你的阅读和「在场」!
文章来自于微信公众号 “AI Humanist by杉森楠”,作者 “AI Humanist by杉森楠”