两名本科生,半年5个顶会!CVPR斩获最佳学生论文提名
CVPR 2026全部奖项揭晓!最佳学生论文荣誉提名颁给了ChordEdit,一作和通讯都是广东工业大学本科在读生。他们用一块7年半前的老Titan,跑完了全部实验。
详细介绍
CVPR 2026颁奖了!
今年CVPR在丹佛举办,共收到16092篇投稿,录用4090篇,录用率25.42%。
刚刚,组委会公布了全部获奖名单。

最佳论文颁给了DeepMind团队的D4RT,最佳学生论文颁给了清华+微软联合团队的TRELLIS.2。
然后是最佳学生论文荣誉提名。
一作Liangsi Lu,广东工业大学。通讯作者Yang Shi,广东工业大学。
两个人都是本科在读。

最佳学生论文提名
一行公式干翻多步推理
论文题目:ChordEdit: One-Step Low-Energy Transport for Image Editing
作者:卢梁司(广东工业大学,一作)、Xuhang Chen(惠州学院)、Minzhe Guo(广东工业大学)、Shichu Li(深圳大学)、Jingchao Wang(北京大学)、Yang Shi(广东工业大学,通讯作者)

两个本科生,组队登顶会
这篇ChordEdit的一作卢梁司(Liangsi Lu)和通讯作者Yang Shi,都是广东工业大学本科在读生。
卢梁司来自数学与统计学院,专业是信息与计算科学,研究方向是表示学习和视觉生成。
在他看来,视觉是人与世界交互的高带宽接口,视觉表示可以捕捉到文本无法描述的规律,帮助AI与人类共同发现物理法则、学习鲁棒的世界模型。
基于这个方向,他做了RLSTG(建模真实世界非欧几何的连续神经动力系统)和ChordEdit(高效稳定地增强生成模型抓取真实语义的编辑框架)。
Yang Shi来自计算机学院,预计2027年毕业,研究方向是计算机视觉和数据挖掘。
两个不同学院的本科生,组成了搭档。
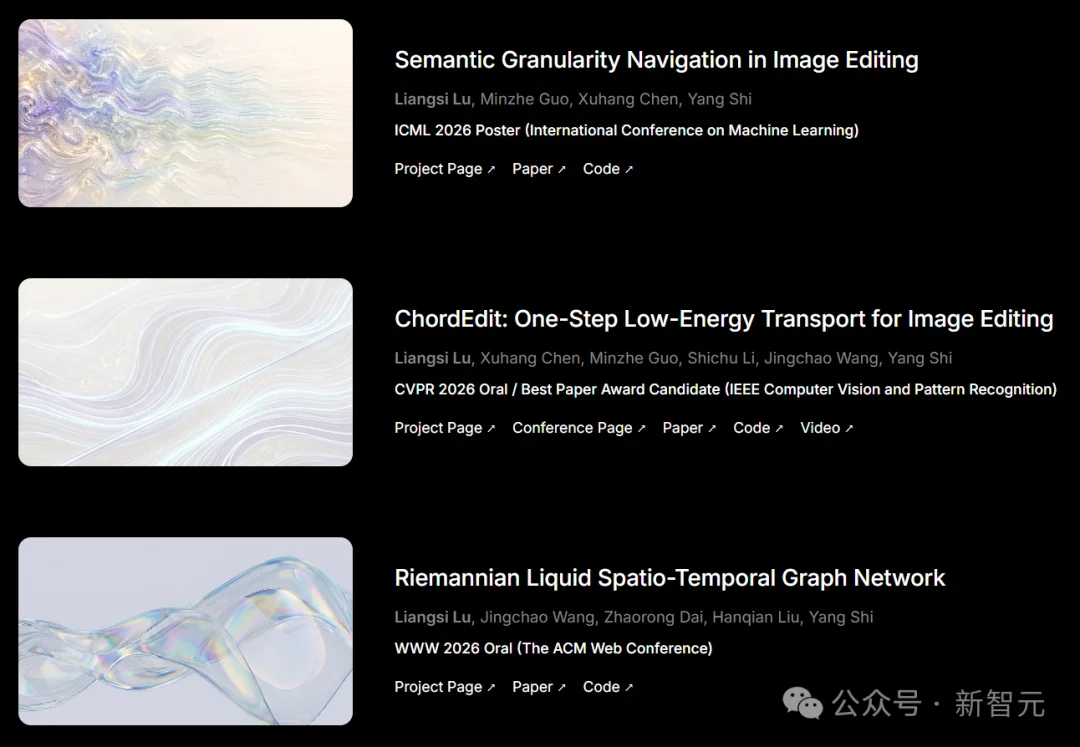
然后他们半年内交出了这样一张成绩单。
Yang Shi的个人主页显示,截至目前他以一作或sole通讯作者身份,入选了5个顶会:
- CVPR 2026(ChordEdit,sole通讯,最佳学生论文提名)
- ICML 2026(sole通讯,图像编辑语义粒度导航)
- KDD 2026(一作,图上的过度挤压问题)
- ACL 2026(一作,多模态推理错误检测基准)
- WWW 2026(sole通讯,黎曼液态时空图网络)
这些工作横跨图像编辑、图神经网络、多模态推理、数据挖掘四个完全不同的方向,从视觉生成到时空图建模,再一路到VLM评测。
问题有多棘手
回到CVPR 2026这篇论文。
如今,一步式文生图模型(SD-Turbo、SwiftBrush这类)已经把生成速度拉到了极限,但速度快的代价是,这类模型做图像编辑的时候几乎不能用。
现有的training-free编辑方法(FlowEdit、Direct Inversion这些),原理上都依赖多步推理来平均掉轨迹中的不稳定性。强行压到一步,画面崩掉。物体扭曲变形,背景乱飘,编辑区和非编辑区的一致性完全丧失。
总结来说就是,一步推理意味着你必须沿着一条极其粗糙的路径,一大步迈到目标位置。路径越粗糙,轨迹能量越高,结果越不可控。
这个问题不是调参能解决的,是数学层面的结构性缺陷。

解法从哪来
卢梁司的解法,来自一套跨越两个世纪的数学。
最优传输问题最早由法国数学家Monge在1781年提出,之后经历了Kantorovich在1940年代的线性规划松弛、Brenier在1991年的二次代价求解。
到2000年,Benamou和Brenier给出了动态最优传输的流体力学形式,也就是ChordEdit直接依赖的框架。
具体来说,ChordEdit把图像编辑重新定义为源分布(原图+原始prompt)和目标分布(原图+编辑后prompt)之间的传输问题。
朴素方法直接拿两个漂移场的差值做编辑,单步推理下噪声极大。ChordEdit则把这个差值场在两个相邻时间点的观测做加权平均,得到一个低能量的Chord Control Field。
这个操作相当于一个时间维度上的平滑算子。漂移场被平滑之后,方差被压下来,能量降下来,天然就适合用一步积分走完全程。
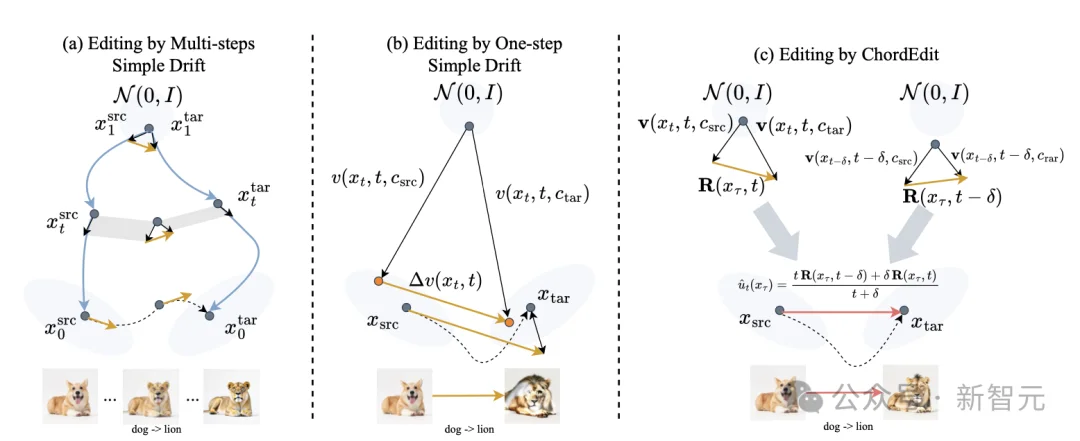
整个方法的核心,浓缩成一个等式(Eq. 4.5),一行加权平均。
Jensen不等式保证能量收缩,平滑后的编辑场方差更低,单步积分的离散化误差随之压缩。
不需要训练。不需要反演。不需要额外的掩码网络。不需要对模型做任何修改。
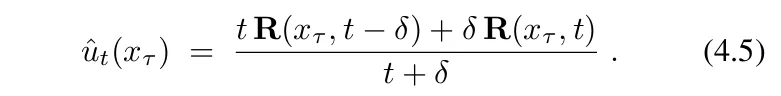
这篇论文总共33页,光附录就写了25页,全是数学证明。从能量为什么会收缩、误差界怎么推、到单步积分为什么能稳定收敛,一路证到底。
消融实验部分则直接可视化了两种编辑场的能量分布。
朴素方法的编辑场能量高且不均匀,对应的就是背景被摧毁、物体变形的区域。ChordEdit的编辑场能量低且平稳,非编辑区域几乎零扰动。

一块消费级显卡跑完
ChordEdit的全部实验,跑在一块2018年发布的NVIDIA Titan 24GB上。推理时显存占用仅7GB。
对比之下,同赛道的SwiftEdit需要15GB,而且还得额外训练一个反演网络。ChordEdit连训练都省了。
速度方面更夸张。比FlowEdit快19倍,比Direct Inversion快208倍。
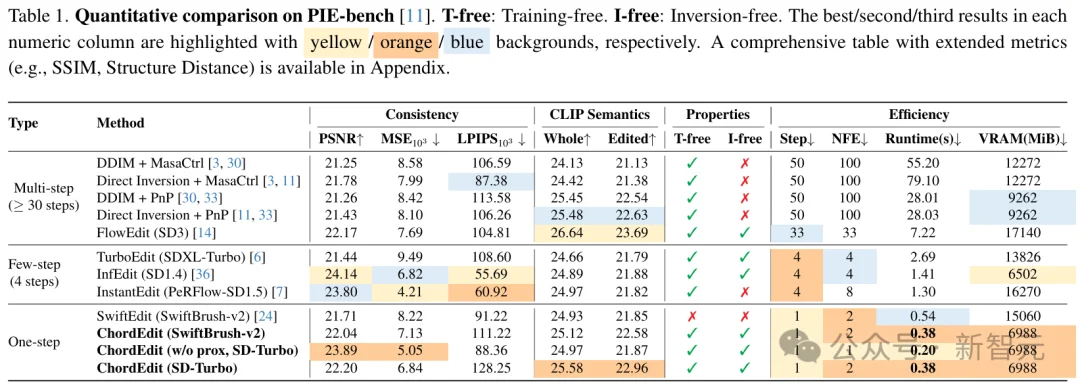
用户研究中,42.5%的参与者在编辑语义准确性上选择ChordEdit,48.3%在背景保持上选择ChordEdit,均为压倒性优势。
而且这个方法是model-agnostic的,SD-Turbo能用,SwiftBrush-v2也能用,换模型不需要改代码、不需要重新训练、不需要调架构。真正的即插即用。

从演示效果看,ChordEdit可以一步完成horse→unicorn、fall→spring、ground→snow等语义编辑,编辑区域跟随prompt变化,非编辑区域保持不变。
这就是低能量传输场的效果,编辑路径足够平滑,非编辑区域几乎零扰动。

从16092篇投稿里,74篇进入最佳论文候选名单(Top 0.45%)。
最终ChordEdit拿到了最佳学生论文提名(Top 0.03%),同时也是Oral。

项目地址:https://chordedit.github.io
开源地址:https://github.com/ChordEdit/ChordEdit
论文地址:https://arxiv.org/pdf/2602.19083
最佳论文:D4RT
论文题目:Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
作者:Chuhan Zhang*、Guillaume Le Moing*、Skanda Koppula*°、Ignacio Rocco*、Liliane Momeni*、Junyu Xie°¹、Shuyang Sun*、Rahul Sukthankar*、Joëlle K. Barral*、Raia Hadsell*、Zoubin Ghahramani*、Andrew Zisserman*°、Junlin Zhang*、Mehdi S. M. Sajjadi*²
机构:*谷歌DeepMind、°伦敦大学学院、°牛津大学
获奖理由:一种优雅且高效的方法,统一了深度估计、相机位姿、3D点追踪和4D点云的推断,结果惊艳。

传统的4D重建方法要么需要为每个任务单独设计解码器,要么要对每一帧做密集解码,计算量极大。
D4RT绕开了这两个瓶颈,设计了一个统一的解码接口,可以独立查询空间和时间中任意一个点的3D位置,不需要逐帧密集处理。
这让整个方法既轻量又可扩展,在多个4D重建基准上全面超越了此前的SOTA。
作者团队阵容强大,Raia Hadsell是DeepMind VP级研究员,Zoubin Ghahramani是DeepMind首席科学家,Andrew Zisserman是牛津大学VGG组创始人。一作Chuhan Zhang此前也在DeepMind从事动态场景重建研究。
最佳学生论文:TRELLIS.2
论文题目:Native and Compact Structured Latents for 3D Generation
作者:Jianfeng Xiang¹²、Xiaoxue Chen¹*、Sicheng Xu²、Ruicheng Wang³²*、Zelong Lv³²*、Yu Deng²、Hongyuan Zhu⁴、Yue Dong²、Hao Zhao¹、Nicholas Jing Yuan⁴、Jiaolong Yang²
机构:¹清华大学、²微软研究院、³中国科学技术大学、⁴微软AI(*为实习期间完成)
获奖理由:一种稀疏、无场的潜在体素表示,在一个开源流水线中统一了开放、非流形、封闭和半透明3D资产的带纹理生成,为几何与外观编码树立了新标准。

技术上,TRELLIS.2的核心是一种叫O-Voxel的「全能体素」结构。相比于传统的3D表示方法,O-Voxel采用的是稀疏体素同时编码几何和外观信息(包括PBR材质参数),不需要依赖多视角2D图像特征的间接监督。
在此基础上,团队设计了Sparse Compression VAE做高压缩率的潜空间编码,然后训练了一个4B参数的flow-matching生成模型。
一作Jianfeng Xiang来自清华大学,工作在Microsoft Research实习期间完成。通讯作者Jiaolong Yang是MSRA的资深研究员,长期深耕3D视觉方向。整个流水线已开源(microsoft/TRELLIS.2)。
最佳论文荣誉提名(2篇)
论文题目:NitroGen: An Open Foundation Model for Generalist Gaming Agents
作者:Loïc Magne¹*、Anas Awadalla¹²*、Guanzhi Wang¹³*†、Yinzhen Xu¹、Joshua Belofsky⁴、Fengyuan Hu¹、Joohwan Kim¹、Ludwig Schmidt²、Georgia Gkioxari³、Jan Kautz¹、Yisong Yue³†、Yejin Choi¹²†、Yuke Zhu¹⁵†、Linxi Fan¹†
机构:¹英伟达、²斯坦福大学、³加州理工学院、⁴芝加哥大学、⁵得克萨斯大学奥斯汀分校
获奖理由:一个4万小时、1000款游戏的数据集,配套评估模拟器和视觉到动作游戏Agent基础模型,打开了新的研究方向。

作者阵容集结了多个领域的顶尖学者。Yejin Choi是ACL 2022主席、MacArthur天才奖得主。Jan Kautz是NVIDIA VP Research。Linxi Fan(范麟熙)是NVIDIA高级研究科学家,此前因MineDojo项目获NeurIPS 2022 Outstanding Paper。

论文题目:SAM 3D: 3Dfy Anything in Images
作者:Xingyu Chen*、Fu-Jen Chu*、Pierre Gleize*、Kevin J Liang*、Alexander Sax*、Hao Tang*、Weiyao Wang*、Michelle Guo、Thibaut Hardin、Xiang Li、Aohan Lin、Jiawei Lin、Ziqi Ma、Anushka Sagar、Bowen Song*、Xiaodong Wang、Jianing Yang*、Bowen Zhang*、Piotr Dollár†、Georgia Gkioxari†、Matt Feiszli‡、Jitendra Malik‡⁺
机构:Meta超级智能实验室(*核心贡献者、†项目负责人、‡同等贡献)
获奖理由:从杂乱的野外单张图片中重建3D物体模型的重大进展,并提供了可扩展的数据采集流水线。

这篇背后站着Meta超级智能实验室的全明星阵容。Jitendra Malik是UC Berkeley的CV泰斗级人物,Piotr Dollár是Meta Research的核心负责人之一,Georgia Gkioxari在今年的NitroGen中也出现了,同时入围两篇Best Paper候选。
时间检验奖
ResNet和YOLO,十年后回来领奖
今年的Longuet-Higgins Test of Time Award颁给了两篇十年前的CVPR 2016经典,ResNet和YOLO。
论文题目:Deep Residual Learning for Image Recognition
作者:何恺明、张祥雨、任少卿、孙剑,微软研究院

这篇提出了残差连接,让深度网络的训练成为可能。在此之前,网络堆到几十层就开始退化,梯度消失是一堵墙。ResNet用一根跳线绕过了这堵墙,152层的网络跑起来比浅层网络还稳。
2015年ImageNet五项第一,错误率3.57%,远低于人类水平(约5.1%)。
十年后回头看,ResNet的残差连接思想已经渗透到了几乎所有的深度学习架构里。从Transformer到扩散模型,跳跃连接是最基础的基础设施之一。

Google Scholar上超过32万次引用
论文题目:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon、Santosh Divvala、Ross Girshick、Ali Farhadi,华盛顿大学

YOLO把目标检测从两阶段流程(先提候选框再分类)压缩成了单阶段的端到端预测,一次前向传播完成定位和分类。速度从秒级拉到了毫秒级,真正让目标检测可以实时运行。
十年过去,YOLO已经迭代到了第11代,仍然是工业界实时检测的首选方案。从自动驾驶到安防监控到工厂质检,YOLO的后代无处不在。
参考资料:
https://chordedit.github.io
https://luliangsi.github.io
https://cnshiyang.github.io
https://cvpr.thecvf.com/Conferences/2026/News/Technical_Program
https://github.com/SkalskiP/top-cvpr-2026-papers
文章来自于微信公众号 “新智元”,作者 “新智元”