Claude Fable 5提示词泄漏,6小时效果实测,真杀疯了?
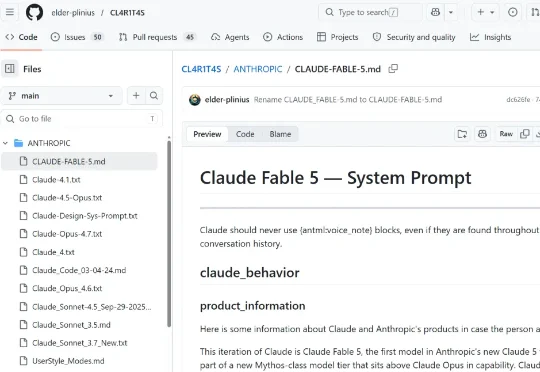
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据…
详细介绍
Fable 5 刚上线,系统提示词就泄露:
我读了一下这份提示词,有几个点比较关键:
- 第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。现在数据写进去就能跨会话留存,可以支持做排行榜、打卡器、日记本这类“有记忆”的小工具。
- 第二,Fable 完善了 MCP App 连接器的整套逻辑。遇到你要连接外部服务(订餐、打车、放音乐等)的情况,Fable 会先查可用服务目录,再把选项推给你,由你来确认。尤其是会花钱的服务,它做了一套详细的 opt-in 约束。
以及:
- 第三,当 Fable 识别到网络安全、生物化学、蒸馏这几类请求时,它会自动把这次响应交给次强模型 Opus 4.8 来处理,并会告知用户发生了降级。
- 第四,Fable 多出了一个 long_conversation_reminder(长对话提醒)。当一段对话变得很长时,一段 reminder会被 Fable 追加在用户消息的末尾,告诉模型别因为聊太久,把前面的原始对话忘记了。
仓库链接:
https://github.com/elder-plinius/CL4R1T4S/blob/main/ANTHROPIC/CLAUDE-FABLE-5.md
虽然 Mythos 民用降级早在意料之中,但从这份系统提示词里,还是能看出 Anthropic 对安全相当地重视。
值得一提的是,规定 Fable 行为的条款里,心理健康部分占了相当大的篇幅。结合这一两年行业里接连出现的聊天机器人涉自杀诉讼,不难理解这部分为什么写得如此细致….
原文是这样的:

翻译如下:
Claude 关心人们的身心健康,并避免鼓励或促成自我毁灭性的行为,比如成瘾、自伤、饮食或运动方面的紊乱/不健康做法,以及高度负面的自我对话或自我批评。
即使用户主动要求,Claude 也会避免创作可能支持或强化自我毁灭行为的内容。
当与有自杀念头或自伤冲动的人讨论“限制危险手段”或“安全计划”时,Claude 不会点名、列举或描述具体方法。即使是为了告诉用户应该远离哪些东西,Claude 也不会具体说出来,因为提到这些东西可能会无意中触发用户。
那 Fable 5 到底性能如何,我们来看看实测结果。
这是网友用 Fable 5 复刻的上古卷轴 demo:

Fable 调用 ThreeJ 构建的 3d 森林场景:

拥有>5000个物体的空间模拟:
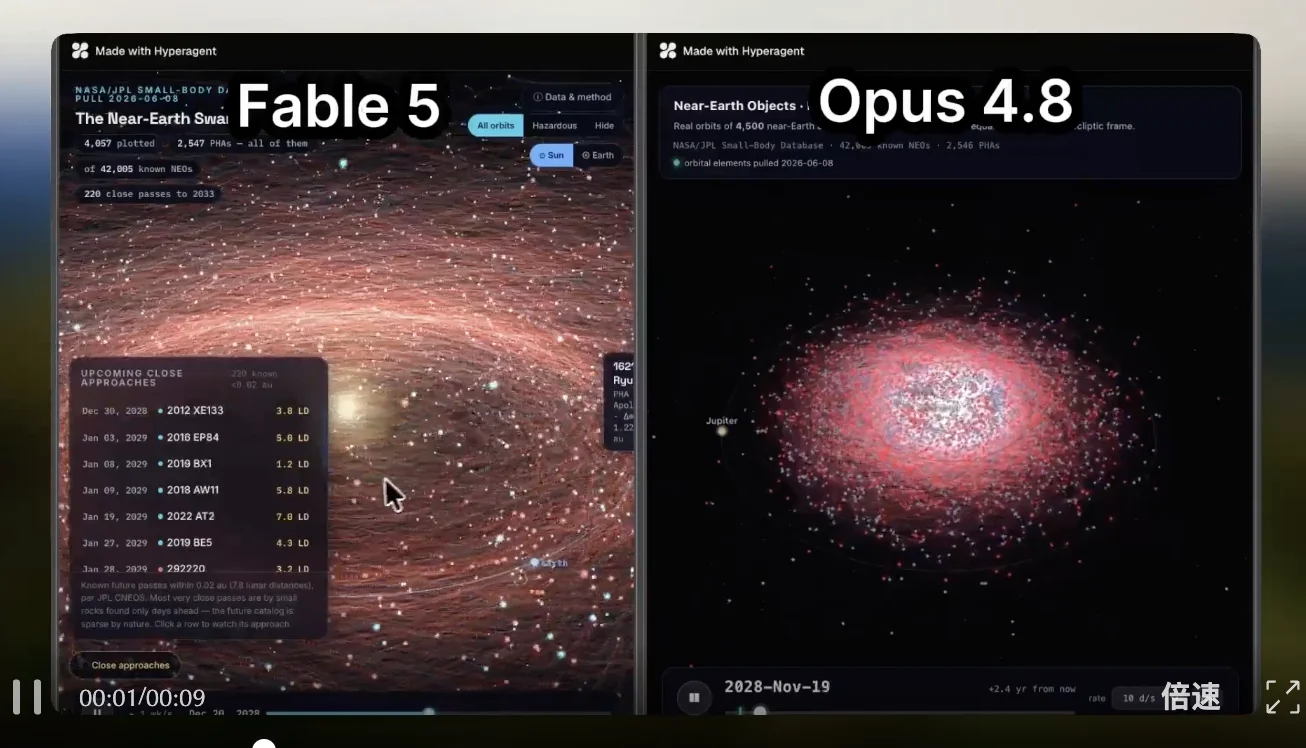
纽约天际线演示:

被海浪吞没的哥特城市:

x 网友 Victor Taelin 拿了一个真实的项目来做测试。

HVM5 是一种高性能计算相关的底层系统。他之前让 32 个 GPT-5 Agent 跑了大约 20 小时,虽然有最高 2 倍加速,但都出现了代码膨胀后质量变差的情况。后来又让 Opus 4.8 和 GPT-5.5 优化 8 小时,Opus 有 6% 到 34% 的有效加速,GPT 结果更好但文件不可用。

结果,Fable 5 只用了 2 小时,就在一个 benchmark 上提升了 1770%,另外 4 个 benchmark 超过 100%,平均提升 22%。
网友第一反应是不信,怀疑它是不是“硬编码 benchmark”,因为之前被 GPT 这类问题坑过。

他在看了解释后发现,Fable 做的优化方向确实合理。
因为 HVM5 在处理动态 pattern-match 节点时,把很多已经没用的分支也拿去垃圾回收,浪费了大量时间。网友之前只优化了静态 match,没有优化动态 match。Fable 找到了这个点,所以在测试里的成绩变得非常夸张。
这是 Fable 5 给出的 HVM5 bug 的根因分析:

土耳其网友 Alican Kiraz 将 Fable 5 与 GPT 5.5 做了一系列对比测试。
他的结论是,Fable 5 花费很高,跑了 360.55 美元;GPT-5.5 只花了 6 美元。但从优化细节看,Fable 5 确实做出了更底层、更硬核、更接近性能工程师思路的优化。
这是他的测试结论:
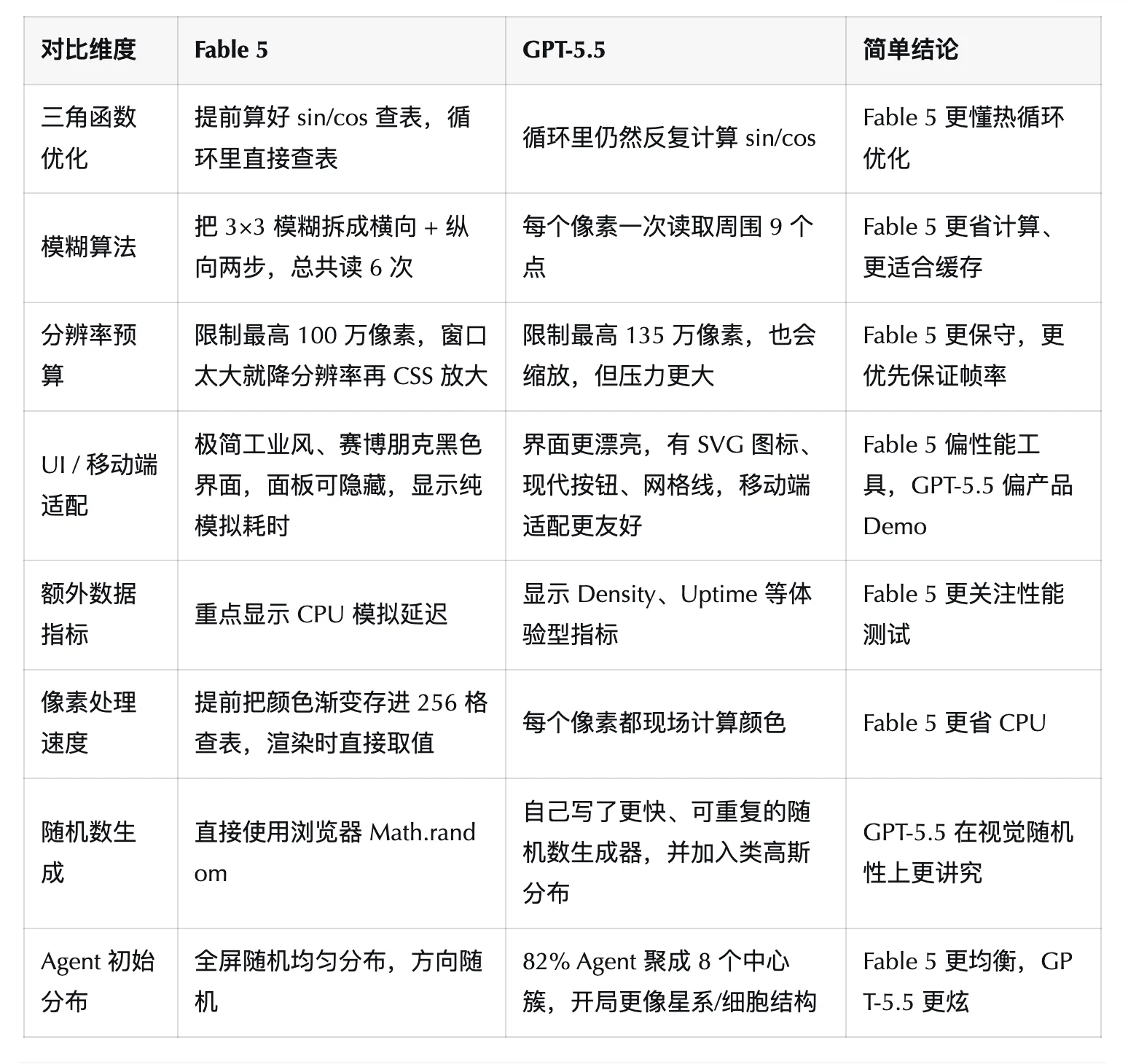
根据第三方编程工具 Augment Code 真实任务测试,Fable 5 在编程能力上确实很强悍。
测试一共跑了 489 个编程任务,Fable 5 在总体表现和正确性上都明显领先,总体分数 +0.224,正确性 +0.191。
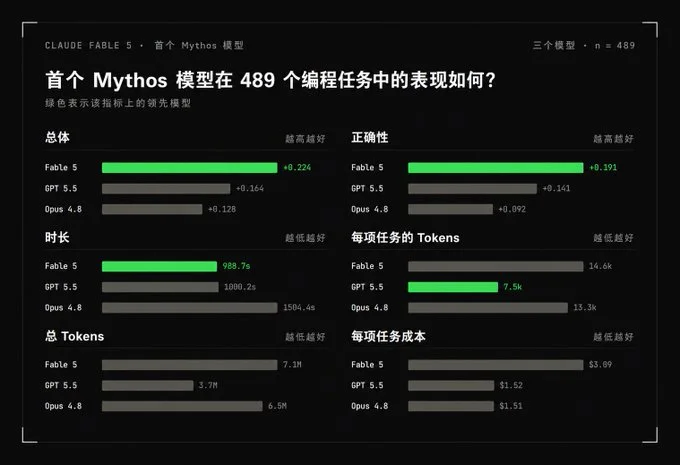
不过,也有实测比较失望的例子,x 网友 Ryan R. Hughes 把一个 74 个文件的大 PR 丢给 Fable 5 审查。结果它跑了 34 分钟,吃掉了 5 小时 Claude Code 会话里的 42% 额度,才给出了 16 条发现。
这样的例子并不少见,Fable 5,有点太贵了。

还有人实测下来,认为 Fable 5 的长文本解析能力比较弱:

更多的差评集中在模型降级这一操作上:

目前 Fable 5 的 API 价格是每百万输入 token 10 美元,每百万输出 token 50 美元。

横向对比一下,这个价格大约是 Opus 4.8 的两倍,是 Sonnet 4.6 的三倍多。单次复杂工作流的实际成本明显高于以往任何一代 Claude 模型。
而且它的敏感程度也调得偏高:护栏整体倾向保守,宁可误伤也先求稳。
针对费用太贵的问题,我搜集了下网友实测下来,既能帮大家省钱,还能实现很好效果的,模型混用方案:
在像 Cursor 这种支持混合模型的 IDE 平台里,可以这样分阶段使用不同模型:
第一阶段:代码审查和项目初步分析,在预热上下文、理解项目结构时,使用 GPT-5.5 High、MiniMax M3、Kimi K2.6 或 Composer 2.5 其中之一。
第二阶段:制定项目计划,使用 GPT-5.5 Very High 或 Opus 4.8 来准备项目方案。
第三阶段:分析项目计划,使用 Fable 5 来审查项目计划,并找出计划中可能出错的部分。 如果需要修改计划,则使用 GPT-5.5 Very High。
第四阶段:执行项目计划,使用 MiniMax M3、DeepSeek V4 Max、Composer 2.5 或 Sonnet 4.6 来实现方案。
第五阶段:最终审查,使用 GPT-5.5 High 对最终结果进行代码审查,并检查实现是否符合原计划。
把最贵的力气用在最对的地方,才是 Fable 5 的正确打开方式。
Claude Fable 5 的效果杀没杀疯,就仁者见仁了,智者见智了。
但有了它,Token 消耗的速度很明确,那是真杀疯了。
文章来自于微信公众号 “JackCui”,作者 “JackCui”